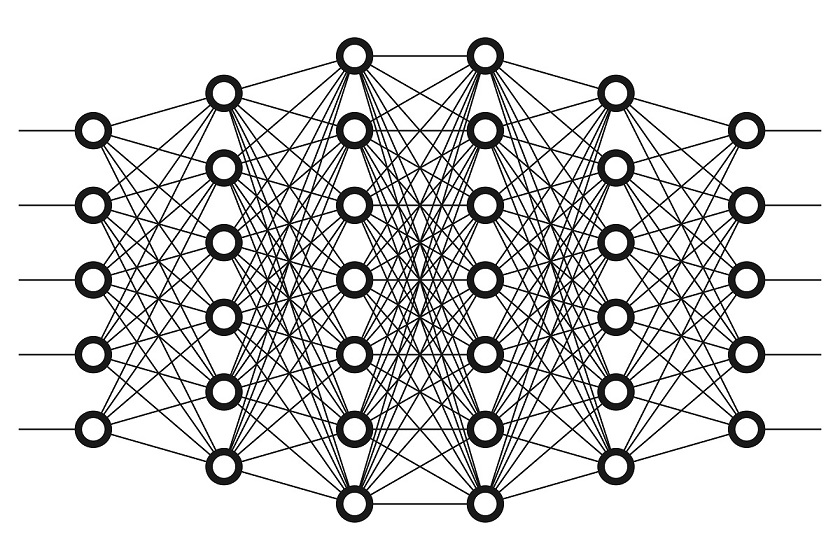
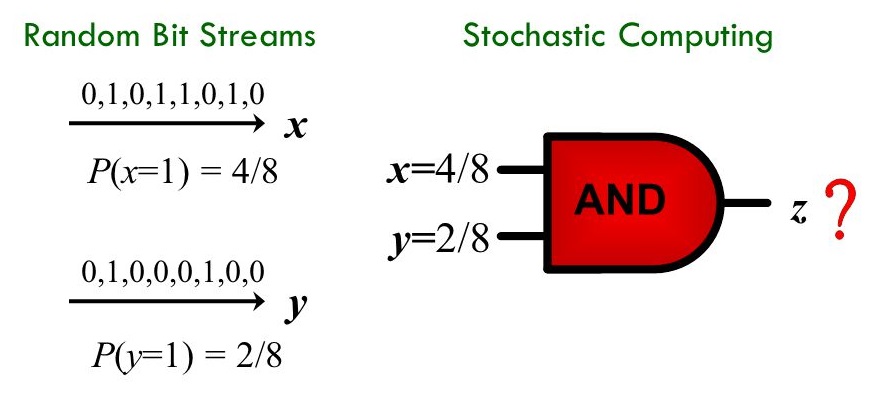
Many techniques have been developed to simplify the testing of device after production. One technic is called "boundary scan" or sometimes referred to as "JTAG" (Joint Test Action Group). Each device that complies with the standard, which was accepted by the IEEE, includes 5 dedicated pins for testing only (AKA TAP – Test Access Port). In this project the students will take an existing logic project, preferably their own VLSI...