
This project proposes building a designated accelerator, which efficiently performs RAM-to-RAM calculations in hardware in a pipeline fashion and thereby dramatically reducing CPU load for machine-learning software applications.
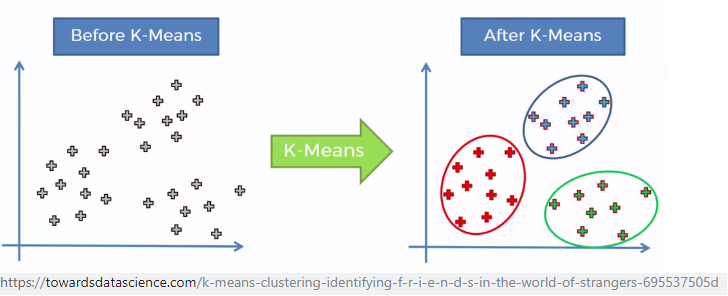
Clustering is a data analysis technique used to get an intuition about the structure of the data.It involves identifying subgroups in the data such that data points in the same subgroup (cluster).
Clustering is considered an unsupervised learning method as the output of the algorithm is not compared with any expected outcome. The aim is to understand the structure of the data by grouping it into subgroups according to a specified criterion.
Clustering is a compute intensive task, and the goal of the project is to implement dedicated hardware to perform these computations in order to offload the CPU/MCU and allow a more power-efficient calculation approach.
Several algorithms can be used for this task. In this project we will select a suitable algorithm (for example K-Means). The algorithm will be adapted to allow hardware implementation and an efficient pipelined architecture will be designed. The design will be simulated, synthesized and its layout will be implemented.
Design goals and challenges
- Learning the basics of Verilog RTL coding language (commonly used in the industry).
- Learning common Machine-Learning standards which are commonly used in the industry.
- Practice in coding design using arch. spec., ramping up an advanced accelerator as an IP
Prerequisite : Digital Systems and Computer Structure – 044252