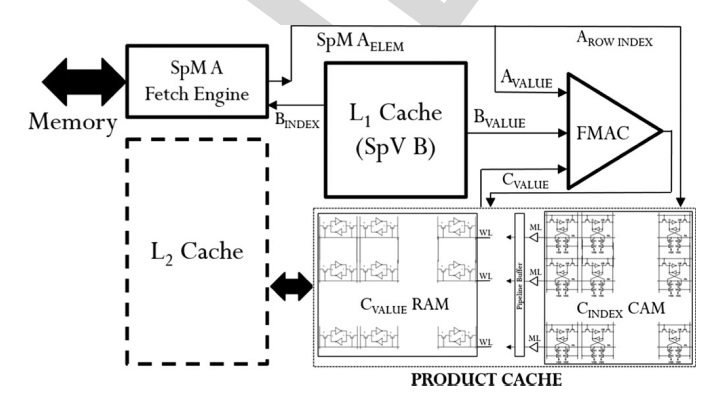
The idea is designing an AXI bus down-sizer (for Read and Write transactions) from any (power-of-two bits) data width source to any (power-of-two bits) data width target, while maintaining (1) the integrity of the transactions, (2) the full data rate (enforced by the narrower side of course) for a predefined outstanding transactions level, and (3) the best optimization accessing any endpoint IP.The project will address AXI3, AXI4, AXI5 flavors (same...